熟悉前端的人都会听过css的伪类与伪元素,然而大多数的人都会将这两者混淆。本文从解析伪类与伪元素的含义出发,区分这两者的区别,并且列出大部分伪类与伪元素的具体用法,即使你有用过伪类与伪元素,但里面总有一两个你没见过的吧。
1.伪类与伪元素
先说一说为什么css要引入伪元素和伪类,以下是css2.1 Selectors章节中对伪类与伪元素的描述:
CSS introduces the concepts of pseudo-elements and pseudo-classes to permit formatting based on information that lies outside the document tree.
直译过来就是:css引入伪类和伪元素概念是为了格式化文档树以外的信息。也就是说,伪类和伪元素是用来修饰不在文档树中的部分,比如,一句话中的第一个字母,或者是列表中的第一个元素。下面分别对伪类和伪元素进行解释:
伪类用于当已有元素处于的某个状态时,为其添加对应的样式,这个状态是根据用户行为而动态变化的。比如说,当用户悬停在指定的元素时,我们可以通过:hover来描述这个元素的状态。虽然它和普通的css类相似,可以为已有的元素添加样式,但是它只有处于dom树无法描述的状态下才能为元素添加样式,所以将其称为伪类。
伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过:before来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中。
2.伪类与伪元素的区别
这里通过两个例子来说明两者的区别。
下面是一个简单的html列表片段:
|
|
<ul>
<li>我是第一个</li>
<li>我是第二个</li>
</ul>
|
如果想要给第一项添加样式,可以在为第一个<li>添加一个类,并在该类中定义对应样式:
HTML:
|
|
<ul>
<li class=“first-item”>我是第一个</li>
<li>我是第二个</li>
</ul>
|
CSS:
|
|
li.first–item {
color: orange
}
|
如果不用添加类的方法,我们可以通过给设置第一个<li>的:first-child伪类来为其添加样式。这个时候,被修饰的<li>元素依然处于文档树中。
HTML:
|
|
<ul>
<li>我是第一个</li>
<li>我是第二个</li>
</ul>
|
CSS:
|
|
li:first–child {
color: orange
}
|
下面是另一个简单的html段落片段:
|
|
<p>Hello World, and wish you have a good day!</p>
|
如果想要给该段落的第一个字母添加样式,可以在第一个字母中包裹一个<span>元素,并设置该span元素的样式:
HTML:
|
|
<p><span class=“first”>H</span>ello World, and wish you have a good day!</p>
|
CSS:
|
|
.first {
font–size: 5em;
}
|
如果不创建一个<span>元素,我们可以通过设置<p>的:first-letter伪元素来为其添加样式。这个时候,看起来好像是创建了一个虚拟的<span>元素并添加了样式,但实际上文档树中并不存在这个<span>元素。
HTML:
|
|
<p>Hello World, and wish you have a good day!</p>
|
CSS:
|
|
p:first–letter {
font–size: 5em;
}
|
从上述例子中可以看出,伪类的操作对象是文档树中已有的元素,而伪元素则创建了一个文档数外的元素。因此,伪类与伪元素的区别在于:有没有创建一个文档树之外的元素。
3.伪元素是使用单冒号还是双冒号?
CSS3规范中的要求使用双冒号(::)表示伪元素,以此来区分伪元素和伪类,比如::before和::after等伪元素使用双冒号(::),:hover和:active等伪类使用单冒号(:)。除了一些低于IE8版本的浏览器外,大部分浏览器都支持伪元素的双冒号(::)表示方法。
然而,除了少部分伪元素,如::backdrop必须使用双冒号,大部分伪元素都支持单冒号和双冒号的写法,比如::after,写成:after也可以正确运行。
对于伪元素是使用单冒号还是双冒号的问题,w3c标准中的描述如下:
Please note that the new CSS3 way of writing pseudo-elements is to use a double colon, eg a::after { … }, to set them apart from pseudo-classes. You may see this sometimes in CSS. CSS3 however also still allows for single colon pseudo-elements, for the sake of backwards compatibility, and we would advise that you stick with this syntax for the time being.
大概的意思就是:虽然CSS3标准要求伪元素使用双冒号的写法,但也依然支持单冒号的写法。为了向后兼容,我们建议你在目前还是使用单冒号的写法。
实际上,伪元素使用单冒号还是双冒号很难说得清谁对谁错,你可以按照个人的喜好来选择某一种写法。
4.伪类与伪元素的具体用法
这一章以含义解析和例子的方式列出大部分的伪类和伪元素的具体用法。下面是根据用途分类的伪类总结图和根据冒号分类的伪元素总结图:
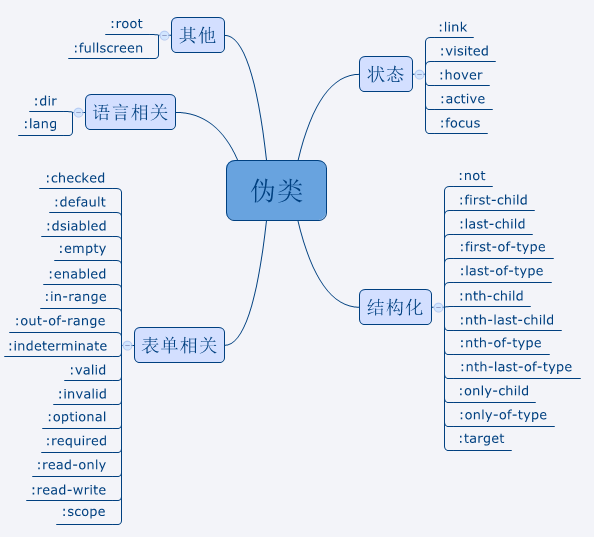
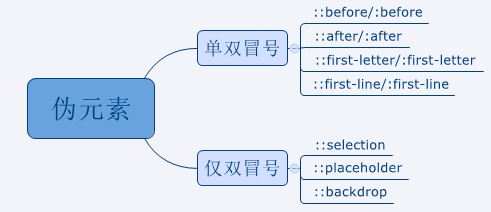
某些伪类或伪元素仍然处于试验阶段,在使用前建议先在Can I Use等网站查一查其浏览器兼容性。处于试验阶段的伪类或伪元素会在标题中标注。
伪类
状态
由于状态伪类的用法大家都十分熟悉,这里就不用例子说明了。
1 :link
选择未访问的链接
2 :visited
选择已访问的链接
3 :hover
选择鼠标指针浮动在其上的元素
4 :active
选择活动的链接
5 :focus
选择获取焦点的输入字段
结构化
1 :not
一个否定伪类,用于匹配不符合参数选择器的元素。
如下例,除了第一个<li>元素外,其他<li>元素的文本都会变为橙色。
HTML:
|
|
<ul>
<li class=“first-item”>一些文本</li>
<li>一些文本</li>
<li>一些文本</li>
<li>一些文本</li>
</ul>
|
CSS:
|
|
li:not(.first–item) {
color: orange;
}
|
2 :first-child
匹配元素的第一个子元素。
如下例,第一个<li>元素的文本会变为橙色。
HTML:
|
|
<ul>
<li>这里的文本是橙色的</li>
<li>一些文本</li>
<li>一些文本</li>
</ul>
|
CSS:
|
|
li:first–child {
color: orange;
}
|
3 : last-child
匹配元素的最后一个子元素。
如下例,最后一个<li>元素的文本会变为橙色。
HTML:
|
|
<ul>
<li>一些文本</li>
<li>一些文本</li>
<li>这里的文本是橙色的</li>
</ul>
|
CSS:
|
|
li:last–child {
color: orange;
}
|
4 first-of-type
匹配属于其父元素的首个特定类型的子元素的每个元素。
如下例,第一个<li>元素和第一个<span>元素的文本会变为橙色。
HTML:
|
|
<ul>
<li>这里的文本是橙色的</li>
<li>一些文本 <span>这里的文本是橙色的</span></li>
<li>一些文本</li>
</ul>
|
CSS:
|
|
ul :first–of–type {
color: orange;
}
|
5 :last-of-type
匹配元素的最后一个子元素。
如下例,最后一个<li>元素的文本会变为橙色。
HTML:
|
|
<ul>
<li>一些文本<span>一些文本</span> <span>这里的文本是橙色的</span></li>
<li>一些文本</li>
<li>这里的文本是橙色的</li>
</ul>
|
CSS:
|
|
ul :last–of–type {
color: orange;
}
|
6 :nth-child
:nth-child根据元素的位置匹配一个或者多个元素,它接受一个an+b形式的参数,an+b匹配到的元素示例如下:
- 1n+0,或n,匹配每一个子元素。
- 2n+0,或2n,匹配位置为2、4、6、8…的子元素,该表达式与关键字even等价。
- 2n+1匹配位置为1、3、5、7…的子元素、该表达式与关键字odd等价。
- 3n+4匹配位置为4、7、10、13…的子元素。
如下例,有以下HTML列表:
1
2
3
4
5
6
7
8
9
10
11
12
|
<ol>
<li>Alpha</li>
<li>Beta</li>
<li>Gamma</li>
<li>Delta</li>
<li>Epsilon</li>
<li>Zeta</li>
<li>Eta</li>
<li>Theta</li>
<li>Iota</li>
<li>Kappa</li>
</ol>
|
CSS:
选择第二个元素,”Beta”会变成橙色:
|
|
ol :nth–child(2) {
color: orange;
}
|
选择位置序号是2的倍数的元素,”Beta”, “Delta”, “Zeta”, “kappa”会变成橙色:
|
|
ol :nth–child(2n) {
color: orange;
}
|
选择位置序号为偶数的元素:
|
|
ol :nth–child(even) {
color: orange;
}
|
选择从第6个开始,位置序号是2的倍数的元素,”Zeta”, “Theta”, “Kappa”会变成橙色:
|
|
ol :nth–child(2n+6) {
color: orange;
}
|
7 :nth-last-child
:nth-last-child与:nth-child相似,不同之处在于它是从最后一个子元素开始计数的。
8 :nth-of-type
:nth-of-type与nth-child相似,不同之处在于它是只匹配特定类型的元素。
如下例,第二个<p>元素会变为橙色。
HTML:
|
|
<article>
<h1>我是标题</h1>
<p>一些文本</p>
<a href=“”><img src=“images/rwd.png” alt=“Mastering RWD”></a>
<p>这里的文本是橙色的</p>
</article>
|
CSS:
|
|
p:nth–of–type(2) {
color: orange;
}
|
9 :nth-last-type
:nth-last-of-type与nth-of-type相似,不同之处在于它是从最后一个子元素开始计数的。
10 :only-child
当元素是其父元素中唯一一个子元素时,:only-child匹配该元素。
HTML:
|
|
<ul>
<li>这里的文本是橙色的</li>
</ul>
<ul>
<li>一些文本</li>
<li>一些文本</li>
</ul>
|
CSS:
|
|
ul :only–child {
color: orange;
}
|
11 :only-of-type
当元素是其父元素中唯一一个特定类型的子元素时,:only-child匹配该元素。
如下例,第一个ul元素只有一个li类型的元素,该li元素的文本会变为橙色。
HTML:
|
|
<ul>
<li>这里的文本是橙色的</li>
<p>这里不是橙色</p>
</ul>
<ul>
<li>一些文本</li>
<li>一些文本</li>
</ul>
|
CSS:
|
|
li:only–of–type {
color: orange;
}
|
12 :target
当URL带有锚名称,指向文档内某个具体的元素时,:target匹配该元素。
如下例,url中的target命中id值为target的article元素,article元素的背景会变为黄色。
URL:
http://example.com/#target
HTML:
|
|
<article id=“target”>
<h1><code>:target</code> pseudo–class</h1>
<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit!</p>
</article>
|
CSS:
|
|
:target {
background: yellow;
}
|
表单相关
1 :checked
:checked匹配被选中的input元素,这个input元素包括radio和checkbox。
如下例,当复选框被选中时,与其相邻的<label>元素的背景会变成黄色。
HTML:
|
|
<input type=“checkbox”/>
<label>我同意</label>
|
CSS:
|
|
input:checked + label {
background: yellow;
}
|
2 :default
:default匹配默认选中的元素,例如:提交按钮总是表单的默认按钮。
如下例,只有提交按钮的背景变成了黄色。
HTML:
|
|
<form action=“#”>
<button>重置</button>
<button type=“submit”>提交</button>
</form>
|
CSS:
|
|
:default {
background: yellow;
}
|
3 :disabled
:disabled匹配禁用的表单元素。
如下例,被禁用input输入框的透明度会变成50%。
HTML:
|
|
<input type=“text” disabled/>
|
CSS:
|
|
:disabled {
opacity: .5;
}
|
4 :empty
:empty匹配没有子元素的元素。如果元素中含有文本节点、HTML元素或者一个空格,则:empty不能匹配这个元素。
如下例,:empty能匹配的元素会变为黄色。
第一个元素中有文本节点,所以其背景不会变成黄色;
第二个元素中有一个空格,有空格则该元素不为空,所以其背景不会变成黄色;
第三个元素中没有任何内容,所以其背景会变成黄色;
第四个元素中只有一个注释,此时该元素是空的,所以其背景会变成黄色;
HTML:
|
|
<div>这个容器里的背景是橙色的</div>
<div> </div>
<div></div>
<div><!— This comment is not considered content —></div>
|
CSS:
|
|
div {
background: orange;
height: 30px;
width: 200px;
}
div:empty {
background: yellow;
}
|
5 :enabled
:enabled匹配没有设置disabled属性的表单元素。
6 :in-range
:in-range匹配在指定区域内元素。
如下例,当数字选择器的数字在5到10是,数字选择器的边框会设为绿色。
HTML:
|
|
<input type=“number” min=“5” max=“10”>
|
CSS:
|
|
input[type=number] {
border: 5px solid orange;
}
input[type=number]:in–range {
border: 5px solid green;
}
|
7 :out-of-range
:out-of-range与:in-range相反,它匹配不在指定区域内的元素。
8 :indeterminate
indeterminate的英文意思是“不确定的”。当某组中的单选框或复选框还没有选取状态时,:indeterminate匹配该组中所有的单选框或复选框。
如下例,当下面的一组单选框没有一个处于被选中时,与input相邻的label元素的背景会被设为橙色。
HTML:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<ul>
<li>
<input type=“radio” name=“list” id=“option1”>
<label for=“option1”>Option 1</label>
</li>
<li>
<input type=“radio” name=“list” id=“option2”>
<label for=“option2”>Option 2</label>
</li>
<li>
<input type=“radio” name=“list” id=“option3”>
<label for=“option3”>Option 3</label>
</li>
</ul>
|
CSS:
|
|
:indeterminate + label {
background: orange;
}
|
9 :valid
:valid匹配条件验证正确的表单元素。
如下例,当email输入框内的值符合email格式时,输入框的边框会被设为绿色。
HTML:
CSS:
|
|
input[type=email]:valid {
border: 1px solid green;
}
|
10 :invalid
:invalid与:valid相反,匹配条件验证错误的表单元素。
11 :optional
:optional匹配是具有optional属性的表单元素。当表单元素没有设置为required时,即为optional属性。
如下例,第一个input的背景不会被设为黄色,第二个input的背景会被设为黄色。
HTML:
|
|
<input type=“text” required />
<input type=“text” />
|
CSS:
|
|
:optional {
background: yellow;
}
|
12 :required
:required与:optional相反匹配设置了required属性的表单元素。
13 :read-only
:read-only匹配设置了只读属性的元素,表单元素可以通过设置“readonly”属性来定义元素只读。
如下例,input元素的背景会被设为黄色。
HTML:
|
|
<input type=“text” value=“I am read only” readonly>
|
CSS:
|
|
input:read–only {
background–color: yellow;
}
|
14 :read-write
:read-write匹配处于编辑状态的元素。input,textarea和设置了contenteditable的HTML元素获取焦点时即处于编辑状态。
如下例,input输入框和富文本框获取焦点时,背景变成黄色。
HTML:
|
|
<input type=“text” value=“获取焦点时背景变黄”/>
<div class=“editable” contenteditable>
<h1>点击这里可以编辑</h1>
<p>获取焦点时背景变黄</p>
</div>
|
CSS:
|
|
:read–write:focus {
background: yellow;
}
|
15 :scope(处于试验阶段)
:scope匹配处于style作用域下的元素。当style没有设置scope属性时,style内的样式会对整个html起作用。
如下例,第二个section中的元素的文本会变为斜体。
HTML:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<article>
<section>
<h1>很正常的一些文本</h1>
<p>很正常的一些文本</p>
</section>
<section>
<style scoped>
:scope {
font-style: italic;
}
</style>
<h1>这里的文本是斜体的</h1>
<p>这里的文本是斜体的</p>
</section>
</article>
|
注:目前支持这个伪类的浏览器只有火狐。
语言相关
1 :dir(处于实验阶段)
:dir匹配指定阅读方向的元素,当HTML元素中设置了dir属性时该伪类才能生效。现时支持的阅读方向有两种:ltr(从左往右)和rtl(从右往左)。目前,只有火狐浏览器支持:dir伪类,并在火狐浏览器中使用时需要添加前缀( -moz-dir() )。
如下例,p元素中的阿拉伯语(阿拉伯语是从右往左阅读的)文本会变成橙色。
HTML:
|
|
<article dir=“rtl”>
<p>التدليك واحد من أقدم العلوم الصحية التي عرفها الانسان والذي يتم استخدامه لأغراض الشفاء منذ ولاده الطفل.</p>
</article>
|
CSS:
|
|
/* prefixed */
article :–moz–dir(rtl) {
color: orange;
}
/* unprefixed */
article :dir(rtl) {
color: orange;
}
|
如下例,p元素中的英语文本会变成蓝色
HTML:
|
|
<article dir=“ltr”>
<p>اIf you already know some HTML and CSS and understand the principles of responsive web design, then this book is for you.</p>
</article>
|
CSS:
|
|
article :–moz–dir(ltr) {
color: blue;
}
/* unprefixed */
article :dir(ltr) {
color: blue;
}
|
2 :lang
:lang匹配设置了特定语言的元素,设置特定语言可以通过为了HTML元素设置lang=””属性,设置meta元素的charset=””属性,或者是在http头部上设置语言属性。
实际上,lang=””属性不只可以在html标签上设置,也可以在其他的元素上设置。
如下例,分别给不同的语言设置不同的引用样式:
HTML:
|
|
<article lang=“en”>
<q>Lorem ipsum dolor sit amet.</q>
</article>
<article lang=“fr”>
<q>Lorem ipsum dolor sit amet.</q>
</article>
<article lang=“de”>
<q>Lorem ipsum dolor sit amet.</q>
</article>
|
CSS:
|
|
:lang(en) q { quotes: ‘“’ ‘”’; }
:lang(fr) q { quotes: ‘«’ ‘»’; }
:lang(de) q { quotes: ‘»’ ‘«’; }
|
其他
1 :root
:root匹配文档的根元素。一般的html文件的根元素是html元素,而SVG或XML文件的根元素则可能是其他元素。
如下例,将html元素的背景设置为橙色
|
|
:root {
background: orange;
}
|
2.:fullscreen
:fullscreen匹配处于全屏模式下的元素。全屏模式不是通过按F11来打开的全屏模式,而是通过Javascript的Fullscreen API来打开的,不同的浏览器有不同的Fullscreen API。目前,:fullscreen需要添加前缀才能使用。
如下例,当处于全屏模式时,h1元素的背景会变成橙色
HTML:
|
|
<h1 id=“element”>在全屏模式下,这里的文本的背景会变成橙色.</h1>
<button>进入全屏模式!</button>
|
JAVASCRIPT:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
var docelem = document.getElementById(‘element’);
var button = document.querySelector(‘button’);
button.onclick = function() {
if (docelem.requestFullscreen) {
docelem.requestFullscreen();
}else if (docelem.webkitRequestFullscreen) {
docelem.webkitRequestFullscreen();
} else if(docelem.mozRequestFullScreen) {
docelem.mozRequestFullScreen();
} else if(docelem.msRequestFullscreen) {
docelem.msRequestFullscreen();
}
}
|
CSS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
h1:fullscreen {
background: orange;
}
h1:–webkit–full–screen {
background: orange;
}
h1:–moz–full–screen {
background: orange;
}
h1:–ms–fullscreen {
background: orange;
}
|
伪元素
1 ::before/:before
:before在被选元素前插入内容。需要使用content属性来指定要插入的内容。被插入的内容实际上不在文档树中。
HTML:
CSS:
|
|
h1:before {
content: “Hello “;
}
|
2 ::after/:after
:after在被元素后插入内容,其用法和特性与:before相似。
3 ::first-letter/:first-letter
:first-letter匹配元素中文本的首字母。被修饰的首字母不在文档树中。
CSS:
|
|
h1:first–letter {
font–size: 5em;
}
|
4 ::first-line/:first-line
:first-line匹配元素中第一行的文本。这个伪元素只能用在块元素中,不能用在内联元素中。
CSS:
|
|
p:first–line {
background: orange;
}
|
5 ::selection
::selection匹配用户被用户选中或者处于高亮状态的部分。在火狐浏览器使用时需要添加-moz前缀。该伪元素只支持双冒号的形式。
CSS:
|
|
::–moz–selection {
color: orange;
background: #333;
}
::selection {
color: orange;
background: #333;
}
|
6 ::placeholder
::placeholder匹配占位符的文本,只有元素设置了placeholder属性时,该伪元素才能生效。
该伪元素不是CSS的标准,它的实现可能在将来会有所改变,所以要决定使用时必须谨慎。
在一些浏览器中(IE10和Firefox18及其以下版本)会使用单冒号的形式。
HTML:
|
|
<input type=“email” placeholder=“name@domain.com”>
|
CSS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
input::–moz–placeholder {
color:#666;
}
input::–webkit–input–placeholder {
color:#666;
}
/* IE 10 only */
input:–ms–input–placeholder {
color:#666;
}
/* Firefox 18 and below */
input:–moz–input–placeholder {
color:#666;
}
|
7 ::backdrop(处于试验阶段)
::backdrop用于改变全屏模式下的背景颜色,全屏模式的默认颜色为黑色。该伪元素只支持双冒号的形式
HTML:
|
|
<h1 id=“element”>This heading will have a solid background color in full–screen mode.</h1>
<button onclick=“var el = document.getElementById(‘element’); el.webkitRequestFullscreen();”>Trigger full screen!</button>
|
CSS:
|
|
h1:fullscreen::backdrop {
background: orange;
}
|
参考文章
1. An Ultimate Guide To CSS Pseudo-Classes And Pseudo-Elements
2. CSS伪类与CSS伪元素的区别及由来
